Automatic Environment Generation to Generalize Agents
Done by: Mohamad H. Danesh, Gaurav Dixit, Ali Raza
In RL, an agent tries to learn the dynamics of an environment by trial and error by interacting with the environment. It is difficult for the agents to learn a general policy that applies across similar environments. Furthermore, they do not get reasonable performances on the same environments of varying difficulty level. To address it, here I try to introduce a new pipeline for generating environments with varying difficulty levels to improve the agents’ performances. Inspired by how humans learn difficult tasks, which basically starts with easy settings and slowly increases the difficulty of the settings, we designed a curriculum learning framework in which the agent first is trained on a simple environment. Then by gradually increasing the difficulty level of the environment, the agent will be fine-tuned on new environments. Finally, it will be able to have a good performance even on the most difficult environments.
Related works
In recent years, a lot of work have been done regarding motion transfer. In one of the proposed approaches, researchers use evolutionary algorithms to tackle this problem. In POET [1], first every environment is paired with an agent, which is controlled by a neural network, that learns how to navigate through the paired environment. Then they use evolutionary algorithms to come up with more advanced environments with the paired agent. In this way, the agent better learns how to gain more rewards, and thus performs better. One approach towards these problems is by changing the location of goal and start state in order to make the environment gradually harder to be solvable for the agent. In [2], the main approach is that by generating a set of feasible start states and then increasingly move it farther away from the goal, the agent learns better general policy eventually. Another approach is conventional coevolutionary algorithms [3]. They are usually divided between competitive coevolution, where agents are rewarded according to their performance against other individuals in a competition in the environment. This way, agents will eventually learn how to have a good performance.
Datasets
We used two different environments for our approach. First one is a modified version of the Bipedal Walker from the famous OpenAI Gym. The other environment, 2D-Bike, is a 2-dimensional physics based bike simulation, in which an agent must learn to drive on a rugged terrain. The terrain is procedurally generated using an input vector consisting of parameters that define its difficulty.
In Bipedal Walker, we use the distance covered by the agent as a measurement of difficulty level of the environment. There are several features of the environment that affect the difficulty level. We use four features of the environment, which are random structures, amplitude, and pit range.
The bipedal walker has a rather intricate walking mechanic which only allows for walking on terrains of limited difficulty. We needed an environment that was scalable linearly in terms of difficulty. We developed the 2D-Bike environment, with exactly this constraint in mind. In the base environment, an agent must learn to navigate a sufficiently smooth terrain as depicted bellow:

The reward is a weighted sum of the distance covered and the average speed. Difficultness is scaled up according to the parameters listed be- low:
-
Noise in terrain generation: This creates structures that are difficult to navigate.
-
Gaps: An agent must learn to gather momentum before jumping over.
-
Stumps: These break momentum and an agent must learn to use lean to overcome them.
-
Reward dynamics: Generated environments are allowed to generate new reward dynamics that reward using just one wheel to complete the track, greater air time, extra rewards for tricks (flips and wheelies).
Framework
We carry out tests and compare three methods to create a learning curriculum. The first approach uses Generative Adversarial Networks (GANs) to learn to generate new environments. The second approach uses a Deep Neural Network to learn the difficulty level (between 0 and 1) given an input image of the environment. The training data is generated by running a trained agent on environments generated by random sampling from a uniform distribution over all parameters. The third approach uses a neuroevolution technique [4], NeuroEvolution of Augmenting Topologies (NEAT) [5], to evolve a generation of deep neural networks. The fitness for an environment in a generation is calculated based on average rewards obtained by a trained agent. Thus, environments where the agent did poorly have a higher fitness and will reproduce to create more such environments. Pruning and mutation allow for harder environments. The overall framework is shown bellow:
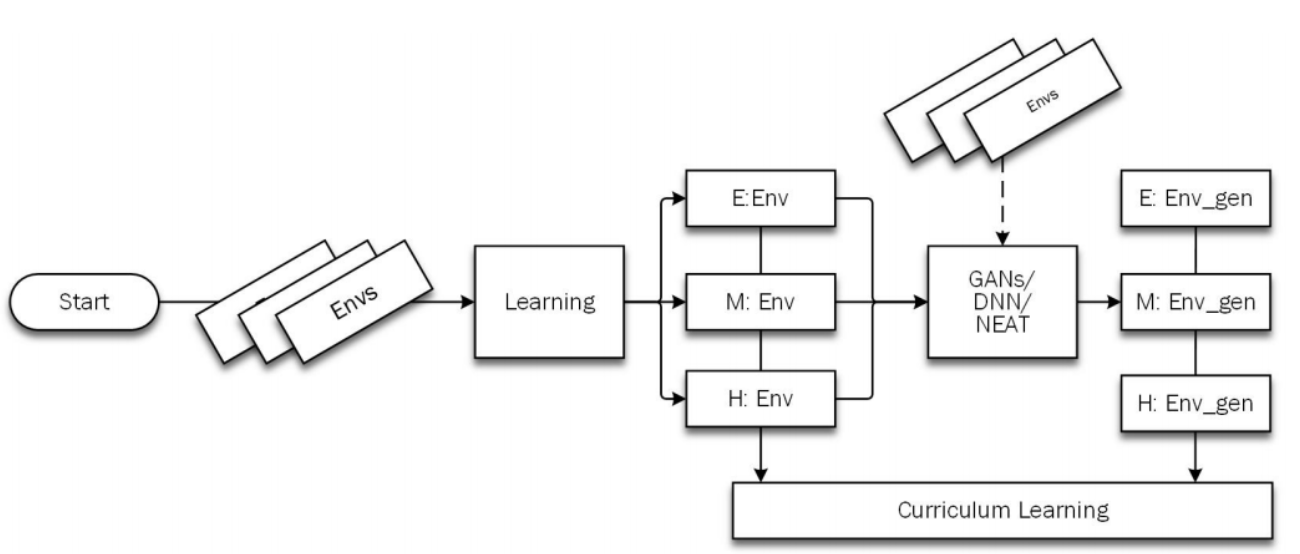
GANs
Features of the environment form an n-dimensional search space where each point corresponds to an environment with a certain difficulty level. We select 100 environments randomly from the search space, and train a vanilla agent on them to get their difficulty levels. We group these environment according to their difficulty as shown bellow:
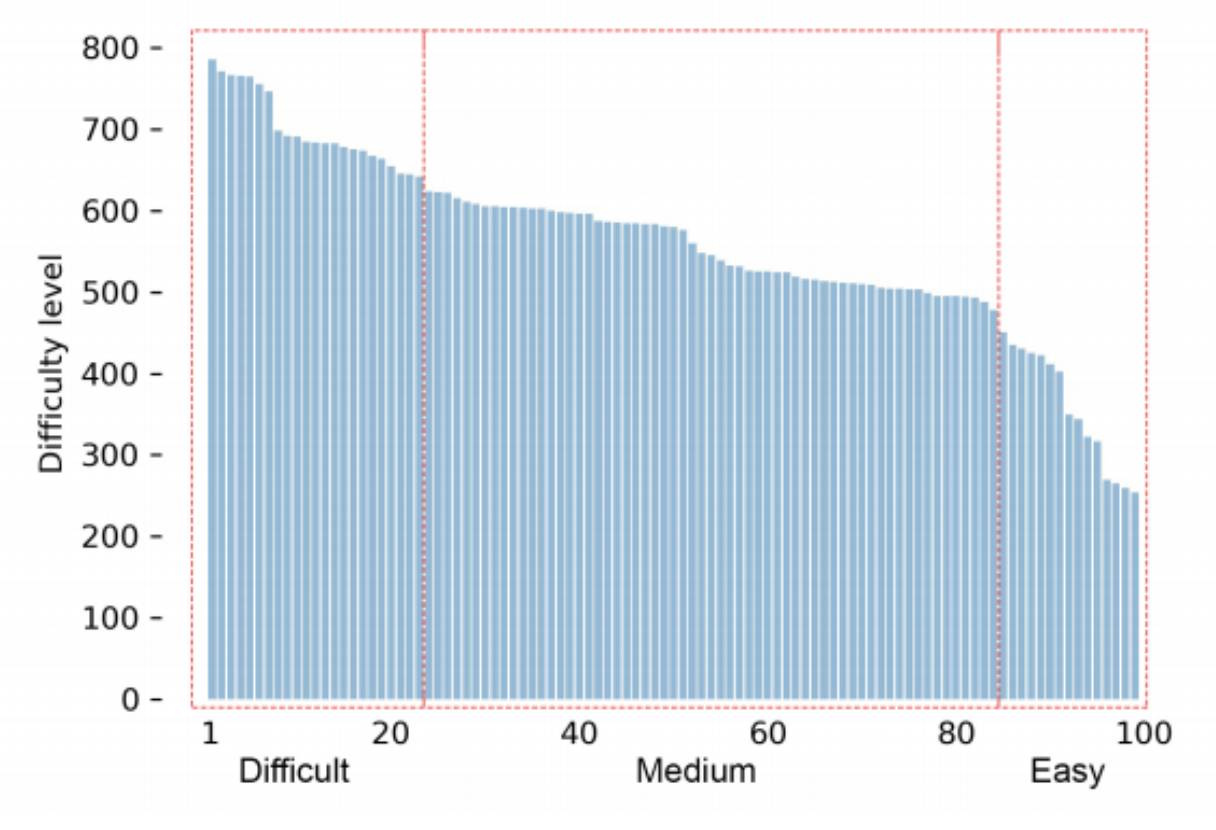
We use GANs to generate new environments corresponding to a certain difficulty level given the environments with the same difficulty level.
DNNs
The objective is to predict the difficulty of an environment based on the agent’s current policy and create a curriculum that helps the agent learn and bootstrap from easier environments. The data set is created by creating environments with parameters sampled from a uniform distribution and evaluating a trained agent on them. The deep neural network is then trained on this data to reduce the loss between the actual distance covered by the agent and the distance predicted by the network.
Neuroevolution of Augmenting Topologies (NEAT)
NEAT has several key features that make it ideal for evolving a population of environments. They are:
Complexification
The networks in the first generation of the population are allowed to be extremely small (perceptrons are also allowed). They add layers, units and connections as they evolve with generations.
Competing Conventions
In most evolutionary algorithms two individuals can encode similar behavior but still have very different genotype. This is competing conventions. When such networks are subject to crossover, the children network are likely to be worse than the parent network. NEAT solves this by keeping historical markings of new structural elements. When a new structural element is created (via structural mutation), it is assigned an innovation number. When two individuals are crossed over, their genotypes are aligned in such a way that the corresponding innovation numbers match and only the differing elements are exchanged.
Speciation and Fitness Sharing
Like some other newer neuroevolution techniques, NEAT also divides its population into several teams, knows as species. This subdivision is based on the dissimilarity of the individuals that is computed based on similar alignment of their genotypes as is used when doing crossover. Probability of crossing over individuals from different species is then much smaller than crossover inside species. By promoting the mating of more similar parent networks, the children are less likely to be worse than the parents because the parents were compatible.
Within a species, the fitness is shared among the individuals. This protects and promotes individuals to mutations - when a mutation happens, the fitness would normally be low but because there is fitness sharing, the individual has time to optimize itself (the weights) to adapt to this new structural change. This indirectly will also promote diversity because the bigger the species, the more is the fitness shared and the less fit are the members of the species.
The fitness in our experiments is a weighted sum of several factors. It is inversely proportional to the average performance (distance covered) by the agents. This implies that the better the agent gets at an environment, the lesser fit it is. To avoid generating environments that are too complex for the policy of the current agent, environments in which the agent is not able to perform above a certain threshold (20% distance covered), are also assigned a low fitness and effectively pruned from the next generation. This allows for a steady increase in difficulty such that the agent can learn harder environments and improve its performance and the environments can evolve every generation simultaneously to slightly increase the overall fitness of all the species of the population.
Experimental results
We use the 2D-Bike environment as the base environment for all three approaches. The initial terrain is an interpolated list of points (smooth). The agent is trained with PPO [6]. The learned policy can solve the environment (complete 100% distance). The agent uses 10 LIDAR sensors that scope out the terrain around the terrain (45 degrees in each direction – partial observability). The input to the agent neural network then is a vector with 10 real valued numbers (distances from LIDAR sensors), the angle of the chassis and the current velocity vector.
The GANs use an initial set of randomly generated environment parameters (labelled with the pre-trained agent’s performance) to create new similar environments.
The Deep neural network is a convolutional network that learns to map 64x64 frames of the environment (pre-processed to highlight the terrain driving line) to the corresponding agent performance (a value between 0 and 1 for the percent of distance that the current agent policy can complete).
NEAT starts with a generation of 10 neural networks with no hidden layers. The topologies are allowed to evolve and create deeper networks with many hidden layers and units.
We use the initial pre-trained agent’s policy as a baseline to compare against its performance when it trains for the entire curriculum.
As can be observed from the figure bellow:
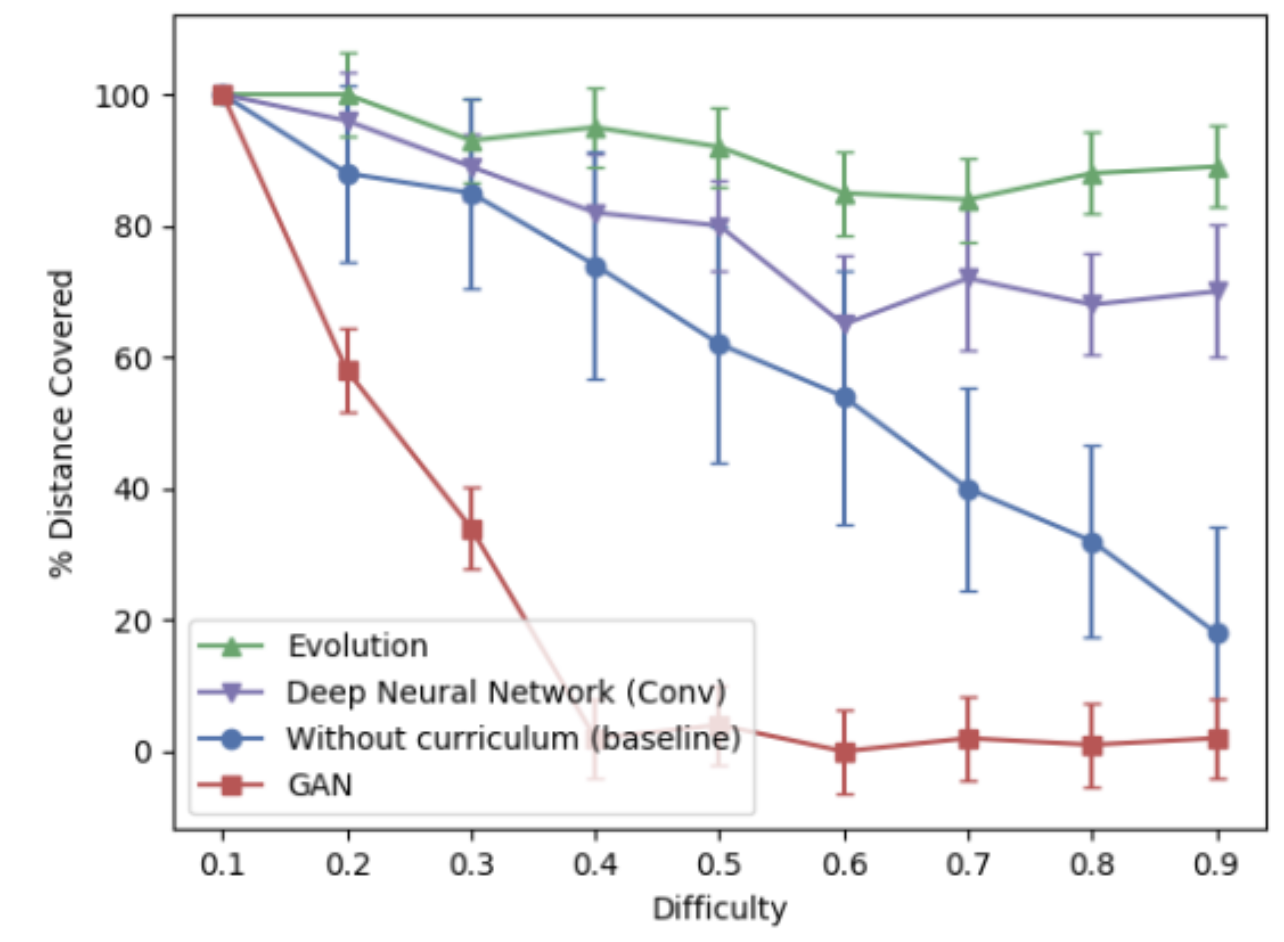
a curriculum generated by our neural network and by NEAT significantly outperforms the baseline. The NEAT generated curriculum grows linearly in difficulty since every new generation of the environment is perturbed only slightly allowing for small incremental changes to the environments. The curriculum generated by the neural network does not generate a curriculum with linear difficulty since it creates the curriculum by randomly searching through the parameter space and will not explore the entire space. The GAN could not be trained to generate environments and completely fails in creating playable (and hence learnable) environments.
We experimented with different architectures, activation functions, and optimization schemes. However, GANs could not lean the dynamics of the environments and failed to produce playable synthetic environments. After a few hundred iterations, discriminator loss converges to 0.6; whereas, generator loss keeps on increasing. We tested our implementation on the MNIST dataset, and as it is shown in Figure bellow:

and we were able to produce reasonable synthetic samples which confirms the correctness of our GANs implementation. The above mentioned results are available here.
Conclusion
In this work, we introduced a new method of learning a curriculum by generating environments of increasing difficulty, which allows agents to generalize learning and improves their performance even on the original base environments. Our experiments show how a curriculum can be generated effectively without having a clear understanding of how harder tasks should be broken down into easier sub tasks. Finally, we see that generating environments with evolutionary methods works much better than a deep neural network since evolution promotes small changes to the parameters of the environment ensuring a continuous and smooth curriculum. On the other hand, since the deep neural network uses random sampling to generate environment parameters, its effectiveness is effectively bound by the amount of search space it can explore.
References
[1] R. Wang, J. Lehman, J. Clune, and K. O. Stanley. Paired open-ended trailblazer (POET): endlessly generating increasingly complex and diverse learning environments and their solutions. CoRR, abs/1901.01753, 2019.
[2] S. Forestier, Y. Mollard, and P.-Y. Oudeyer. Intrinsically motivated goal exploration processes with automatic curriculum learning. arXiv preprint arXiv:1708.02190, 2017.
[3] J. B. Pollack. Challenges in coevolutionary learning : Arms-race dynamics , open-endedness , and mediocre stable. 1998.
[4] F. P. Such, V. Madhavan, E. Conti, J. Lehman, K. O. Stanley, and J. Clune. Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning, 2019.
[5] K. O. Stanley and R. Miikkulainen. Evolving neural networks through augmenting topologies. Evol. omput., 10(2):99–127, June 2002.
[6] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.