Exploration and Generalization in Reinforcement Learning
Conservative uncertainty estimation by fitting prior networks:
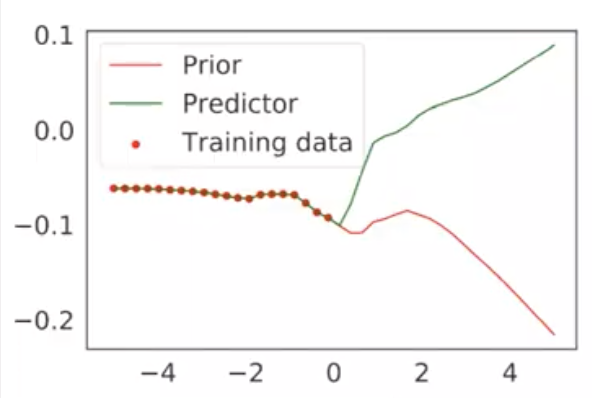
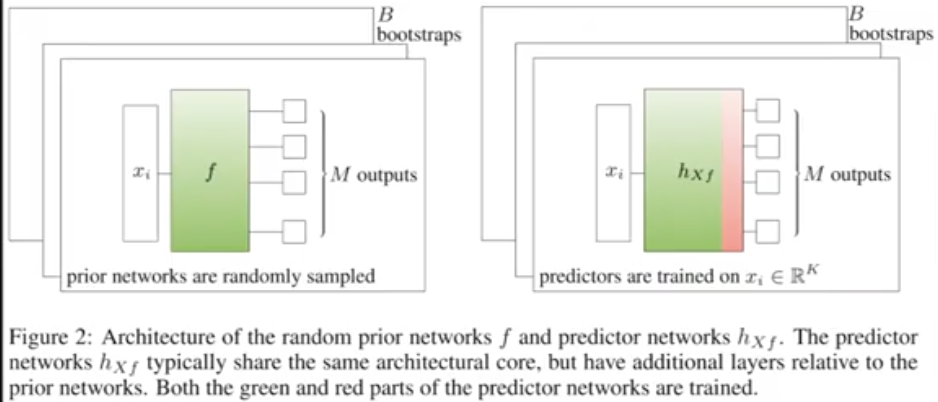
By using random prior networks and comparing its output with the learnable network, one can easily determine the level of uncertainty regarding the given input data. The more uncertain, the more unseen that data is, thus is a good option for exploration. Once the data is given to the learnable network, it tries to match its output to the one from the random prior network.
It is worth noting that these two networks mostly have the same architecture:
Theoretical results:
Having theoretical results with function approximators and in a domain with high dimensional data are quite important and hard. First, random prior uncertainty estimates are conservative, meaning that it can be guaranteed to not over-confident which is very important in safety critical applications of ML and RL. Second, random priors are guaranteed to concentrate with infinite data, meaning that the more data that is used, eventually, these estimates will converge.
Variational deep RL (VariBad):
Key idea: learn to learn new tasks in simulation, learn to rapidly adapt to real new tasks.
The aim is to flexibly learn bayes-optimal behavior for rapid online adaptation with minimal assumptions.
There is a recurrent encoder which learns variational trajectory embeddings, known as belief. The point of having recurrent network is to maintain information through multiple steps. The belief has a lower dimensions compared to states and actions:
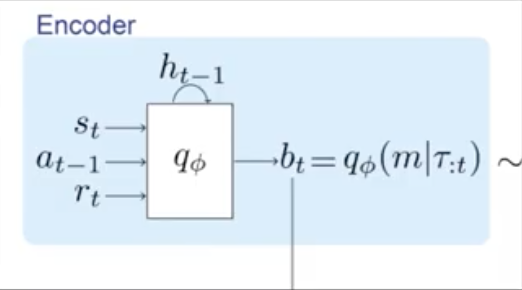
With the belief that the encoder embeds, there are two things to be done.
Decoder: Learns to predict future states and rewards. The encoder-decoder pipeline forces the agent to maintain a belief that is relevant to predicting the future.
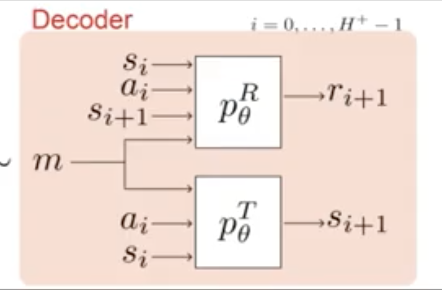
And finally the agent conditions policy based on its belief. The policy learns approximately bayes-optimal behavior given current belief.
Generalization in RL with selective noise injection and information bottleneck:
First insight: Selective noise injection is valuable, meaning that instead of applying regularization across to all the components, it applies the noise to the components that are most helpful. For example, it does not apply noise to the components regarding the exploration, because originally it has noise embedded in it (e.g. the behavior rollout policy). Doing this speeds up the learning process.
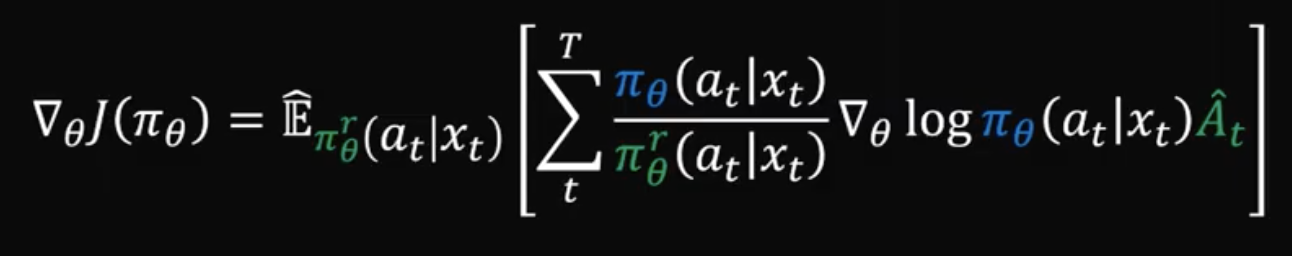
Second insight: Regularization with information bottleneck is particularly effective. Because in the low data regime, e.g. in RL, it is valuable to compress observations that are available to the agent to only learn those features that provide additional features, for a particular task.