Abstract
World models promise a paradigm shift in robotics, where an agent learns the underlying physics of its environment once to enable efficient planning and behavior learning. However, current world models are often hardware-locked specialists: a model trained on a Boston Dynamics Spot robot fails catastrophically on a Unitree Go1 due to the mismatch in kinematic and dynamic properties, as the model overfits to specific embodiment constraints rather than capturing the universal locomotion dynamics. Consequently, a slight change in actuator dynamics or limb length necessitates training a new model from scratch. In this work, we take a step towards a framework for training a generalizable Quadrupedal World Model (QWM) that disentangles environmental dynamics from robot morphology. We address the limitations of implicit system identification, where treating static physical properties (like mass or limb length) as latent variables to be inferred from motion history creates an adaptation lag that can compromise zero-shot safety and efficiency. Instead, we explicitly condition the generative dynamics on the robot's engineering specifications. By integrating a physical morphology encoder and a reward normalizer, we enable the model to serve as a neural simulator capable of generalizing across morphologies. This capability unlocks zero-shot control across a range of embodiments. Since the policy is conditioned on generalizable latent dynamics provided by the world model, we can deploy the agent on entirely unseen quadrupeds without fine-tuning, adaptation, or warm-up periods. We introduce, for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion. While we carefully study the limitations of our method, QWM operates as a distribution-bounded interpolator within the quadrupedal morphology family rather than a universal physics engine, this work represents a significant step toward morphology-conditioned world models for legged locomotion.
Overview
Method
QWM extends DreamerV3 with three targeted architectural changes to handle cross-morphology generalization:
Training QWM required running eight different robot morphologies in parallel within a single simulator, something Isaac Lab does not support out of the box. To enable this, we built Hetero-Isaac, an extension to NVIDIA Isaac Lab that assigns distinct robot morphologies, collision geometries, and kinematic trees to different environment subsets while keeping all physics fidelity intact. The full technical details of this infrastructure, including joint-order unification, index mapping, and padded reward functions, are described in the accompanying blog post: Heterogeneous Environments in Isaac Lab.
Real-World Experiments
Both Unitree Go1 and ANYmal-D were held out during training. By injecting the correct morphology embedding, the frozen policy achieves stable locomotion on both platforms with zero falls across 20 trials (10 per platform, 60 seconds each).



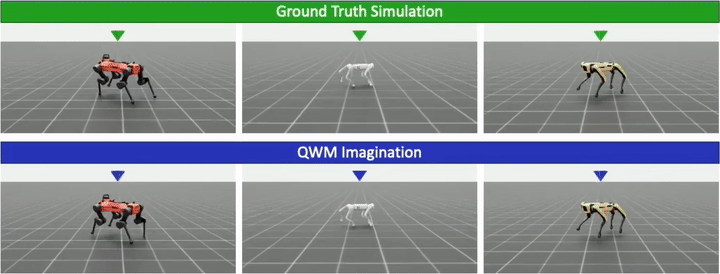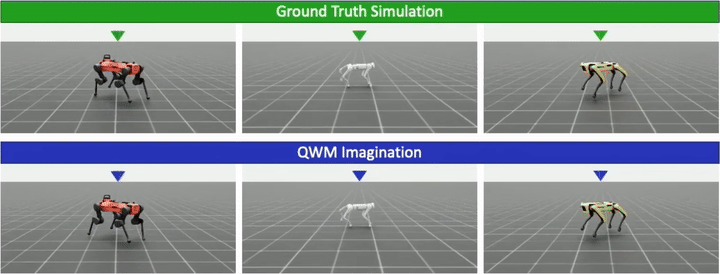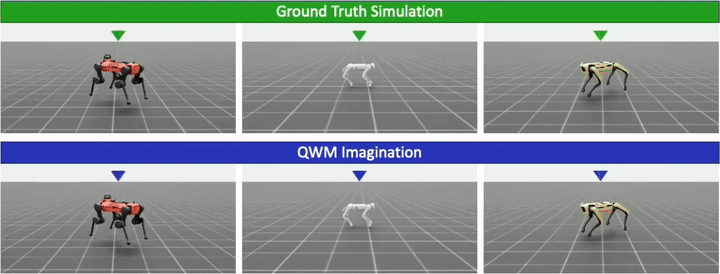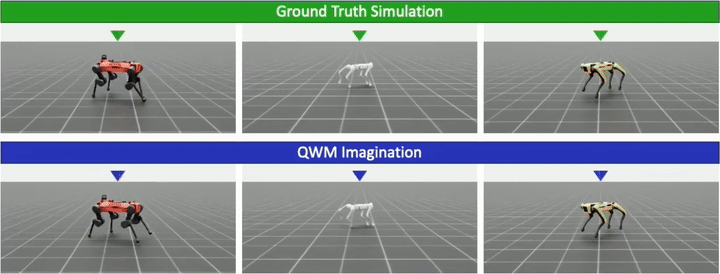
Multi-Morphology Mastery
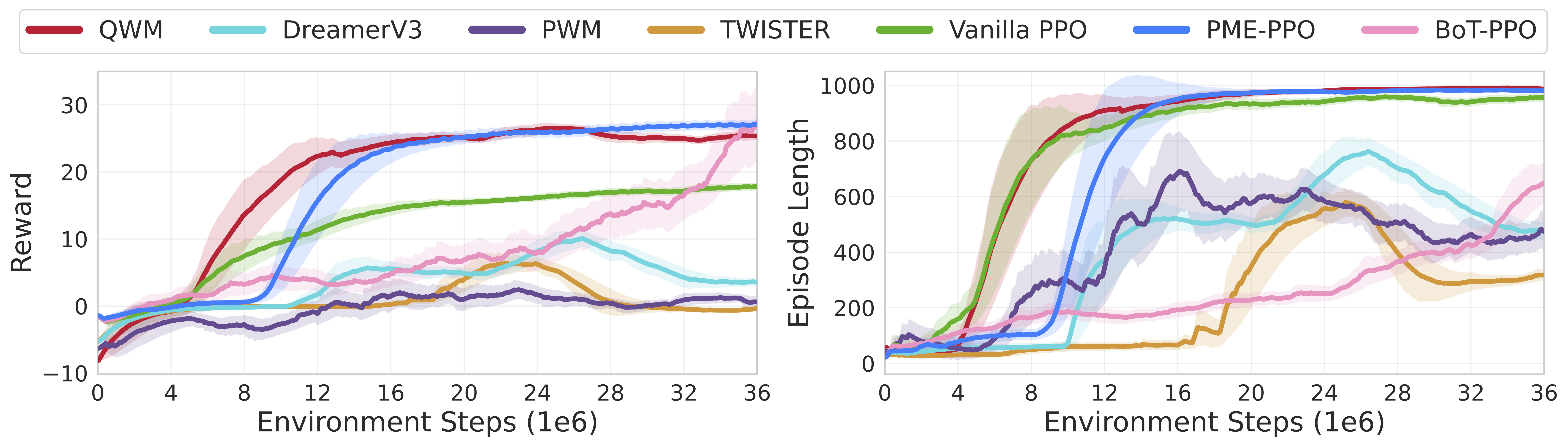
A single QWM is trained simultaneously on the full heterogeneous cohort of eight quadrupeds and compared against world model baselines (DreamerV3, PWM, TWISTER) as well as a model-free oracle (PME-PPO).